There is a multitude of measures in social network analysis (SNA). In other social sciences, great lengths are gone to develop robust and valid measures, with discrete validity, which means there are relatively few overlapping constructs; and some remain standard for decades. Not so in SNA. Take the measure of centrality, a basic building block; which essentially identifies the most important nodes / vertices in a network. The most basic one is degree centrality, which just counts the number of links a node has. The more links, the more popular. But there are others. Many others.
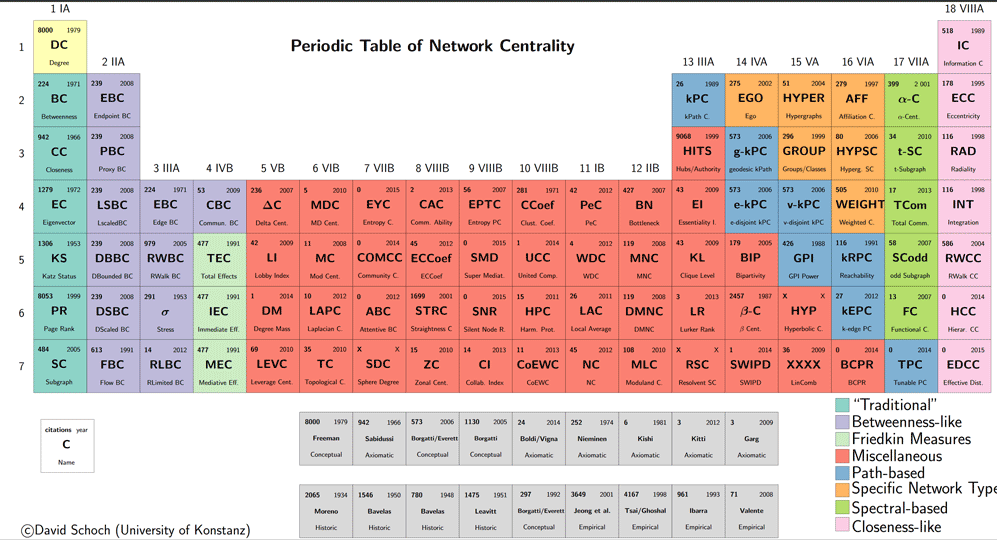
A table of a sample of such indices count 108 different measures, organized as a “periodic table”.(click image for interactive version)
These include common ones such as betweenness centrality, a measure of how often a given node is part of the shortest path between any other nodes; eigenvector centrality, which looks at the importance of every node, and ranks nodes as to how important their ties are. Then there is Pagerank, named after Larry Page, a founder of Google, which is the basic algorithm google used to rank webpages in the early days. The list goes on.
All being a measure of centrality, the measures are highly correlated. However, this does not mean they are interchangeable, as the measures have subtle, but distinct differences. It is the underlying research question that should decide which measure is the most correct. For example, if the question relates to what nodes are the most important for ensuring information is spread, betweenness centrality, or Flow BC may be good options, while if the question is what topics in a keyword map receive the most attention, eigenvector centrality may be a better solution.
However the fact they are most often very highly correlated offers potential more insights, at least when they are not highly correlated. I came across this insight in a great video on Youtube, on “Whole Network Descriptive Statistics”, given my Molly Copeland at Duke. I have taken a slide she presented, and reproduce it here:
Centrality: Individual nodes – comparing measures.
When two measures are highly correlated at the network level, it indicates that there are nodes that have very different values. Identifying these nodes can indicate the following.
| Low degree | Low Closeness | Low Betweenness | |
| High degree | Node is embedded in cluster that is an outlier in the full network | Node’s connections are redundant; information may flow past them. | |
| High closeness | Node is a key actor tied to important / active alters | Probably multiple paths in the network; Node is near many others; as are many others | |
| High betweenness | Node few ties are crucial for network flow | Very rare. Means ego monopolizes ties from a few, who in turn have many connections |
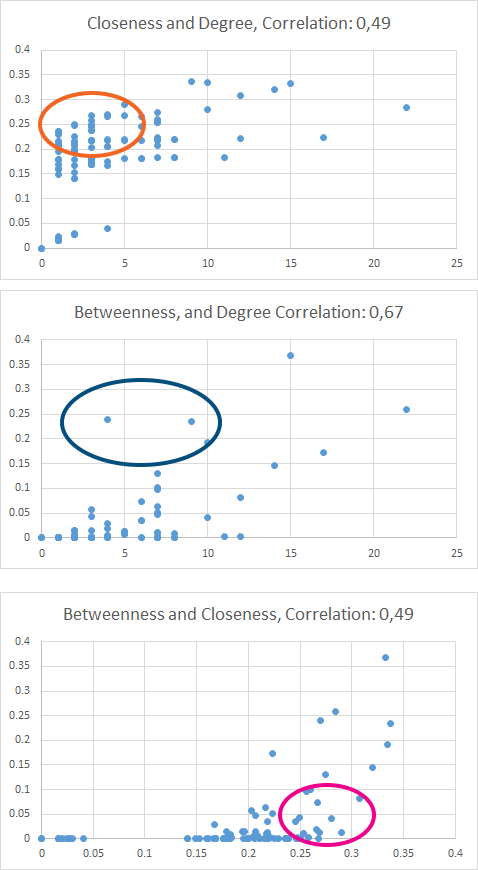
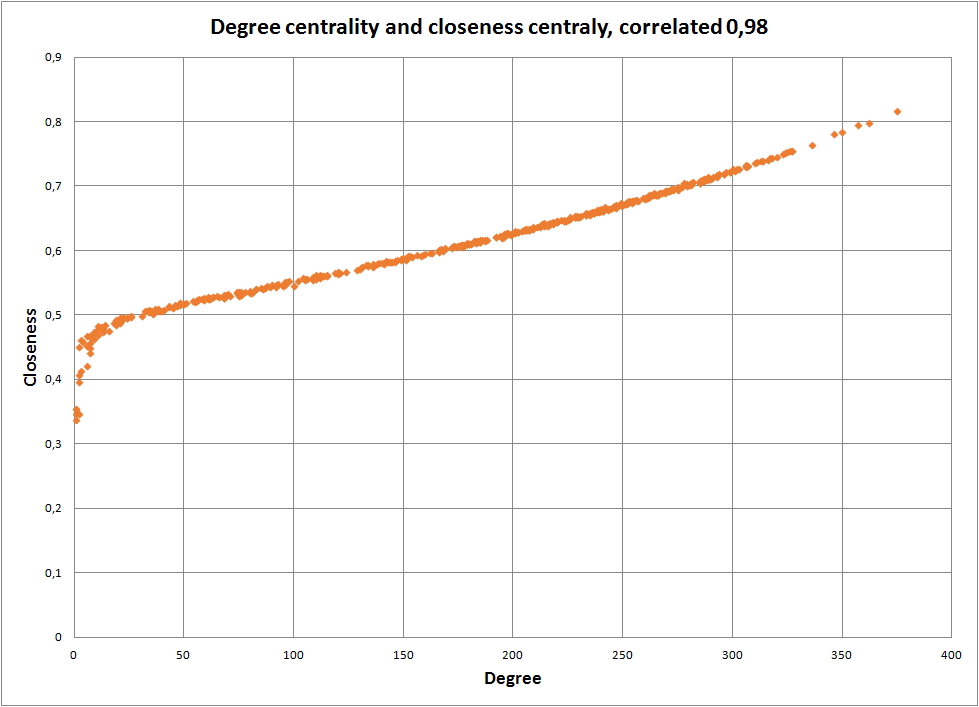
To test this out, I examined two graphs, one bibliometric coupling graph (for a paper I am working on, thus not shown here), where two centrality measures have a 0,98 correlation. The second graph, is that of the authorship network in the department where I work. Here, the correlations are between 0,5 and 0,7. A graphical examination of the data shows that some of the staff do fit in with the boxes above, as colour coded.